
Building POS Tagger
Part-of-Speech (POS) tagging is a fundamental task in Natural Language Processing that involves assigning grammatical categories to each word in a text. These categories include nouns, verbs, adjectives, adverbs, prepositions, conjunctions, determiners, and others. POS tagging serves as a crucial preprocessing step for many advanced NLP applications.
The POS Tagging Problem
Consider the sentence: "The can can hold water."
Without context, it's unclear how to tag the word "can":
- First "can" → NOUN (container)
- Second "can" → VERB (ability)
This ambiguity makes POS tagging a challenging computational problem that requires sophisticated algorithms to resolve.
Grammatical Categories (POS Tags)
Common POS Tags (Penn Treebank Tagset)
| Tag | Category | Example | Description |
|---|---|---|---|
| NN | Noun (singular) | cat, tree | Person, place, thing, or concept |
| NNS | Noun (plural) | cats, trees | Plural form of noun |
| VB | Verb (base form) | run, eat | Action or state word |
| VBD | Verb (past tense) | ran, ate | Past tense verb |
| VBG | Verb (gerund) | running, eating | Present participle/-ing form |
| JJ | Adjective | big, red | Descriptive word |
| RB | Adverb | quickly, very | Modifies verbs, adjectives |
| DT | Determiner | the, a, an | Specifies nouns |
| IN | Preposition | in, on, at | Shows relationships |
| CC | Conjunction | and, but, or | Connects words/phrases |
| PRP | Pronoun | he, she, it | Replaces nouns |
Challenges in POS Tagging
1. Lexical Ambiguity
Many words can serve multiple grammatical functions:
- Book: "I book a flight" (VERB) vs. "Read the book" (NOUN)
- Fast: "Drive fast" (ADVERB) vs. "A fast car" (ADJECTIVE)
2. Unknown Words
New words, proper nouns, and domain-specific terms not seen during training pose significant challenges.
3. Contextual Dependencies
The correct tag often depends on surrounding words and broader sentence structure.
POS Tagging Algorithms
1. Hidden Markov Models (HMM)
HMMs model POS tagging as a sequence labeling problem using:
Transition Probabilities: P(tagi | tag{i-1})
The probability of a tag given the previous tag(s).
Emission Probabilities: P(word_i | tag_i)
The probability of observing a word given its tag.
Mathematical Foundation:
Best tag sequence = argmax P(tags | words)
= argmax P(words | tags) × P(tags)
Viterbi Algorithm:
Uses dynamic programming to find the most likely tag sequence efficiently.
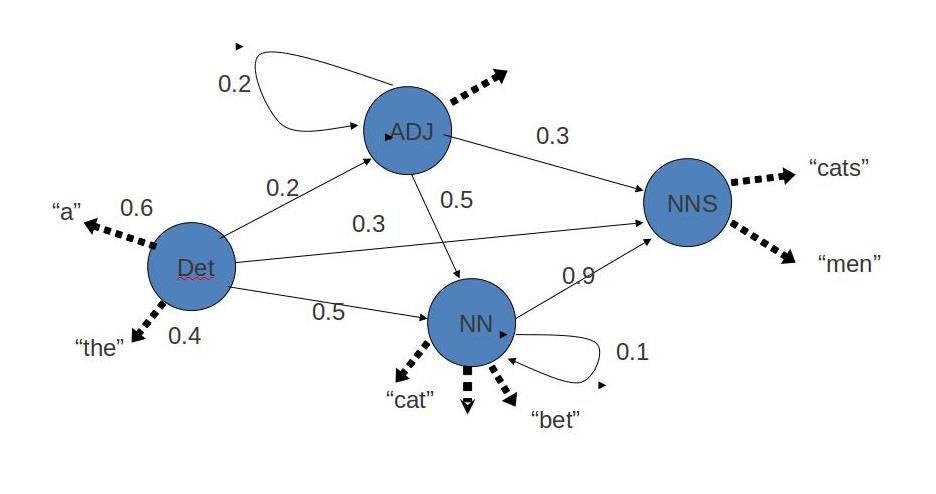
Figure: HMM architecture showing states (POS tags), transitions (tag-to-tag probabilities), and emissions (tag-to-word probabilities)
2. Conditional Random Fields (CRF)
CRFs overcome HMM limitations by:
Global Optimization:
Consider the entire sequence simultaneously rather than making local decisions.
Rich Feature Sets:
Incorporate multiple features:
- Word prefixes and suffixes
- Capitalization patterns
- Word length
- Neighboring word features
- Regular expression patterns
No Independence Assumptions:
Unlike HMMs, CRFs don't assume conditional independence of observations.
Mathematical Framework:
P(y|x) = (1/Z(x)) × exp(Σ λ_k f_k(y_i, y_{i-1}, x, i))
Where:
y= tag sequencex= word sequencef_k= feature functionsλ_k= feature weightsZ(x)= normalization factor
Context Features
Unigram Features
Consider only the current word:
- Limited disambiguation capability
- Fast computation
- Baseline approach
Bigram Features
Consider current and previous tag:
P(tag_i | tag_{i-1})- Better context modeling
- Improved accuracy over unigrams
Trigram Features
Consider current and two previous tags:
P(tag_i | tag_{i-1}, tag_{i-2})- Rich contextual information
- Higher computational complexity
- Risk of data sparsity
Training Corpus Considerations
Corpus Size Impact
Small Corpus (< 10K sentences):
- Limited coverage of word-tag combinations
- Poor handling of rare constructions
- Higher error rates on unseen data
Medium Corpus (10K-100K sentences):
- Better statistical estimates
- Improved handling of common ambiguities
- Reasonable performance trade-off
Large Corpus (> 100K sentences):
- Robust statistical models
- Better generalization
- Diminishing returns beyond certain point
Data Quality Factors
- Domain Coverage: Diverse text types (news, literature, technical)
- Annotation Consistency: Uniform tagging standards
- Linguistic Variation: Different writing styles and registers
Evaluation Metrics
Accuracy
Accuracy = (Correctly tagged words) / (Total words) × 100%
Per-Class Metrics
- Precision: Correct tags of type X / All predicted tags of type X
- Recall: Correct tags of type X / All actual tags of type X
- F1-Score: Harmonic mean of precision and recall
Error Analysis
- Confusion Matrix: Shows which tags are confused with others
- Unknown Word Performance: Accuracy on out-of-vocabulary terms
Applications of POS Tagging
1. Syntactic Parsing
POS tags provide essential input for parsing algorithms that determine sentence structure.
2. Information Extraction
Identifying entities and relationships often relies on POS patterns:
- "PERSON VERB LOCATION" patterns
- Named entity recognition
3. Machine Translation
POS tags help align words correctly across languages and maintain grammatical structure.
4. Text Classification
POS tag distributions can serve as features for genre classification, authorship attribution, etc.
5. Question Answering
Understanding grammatical roles helps in matching questions to appropriate answer spans.
Neural Approaches
- BiLSTM-CRF: Combines recurrent neural networks with CRF layers
- BERT-based Models: Transformer architectures achieving state-of-the-art results
- Multilingual Models: Single models handling multiple languages
Practical Considerations
- Speed vs. Accuracy Trade-offs: Real-time applications vs. research settings
- Domain Adaptation: Adapting models to specific domains (medical, legal, social media)
- Multi-task Learning: Joint training with related tasks like named entity recognition
Conclusion
POS tagging represents a fundamental bridge between raw text and structured linguistic analysis. Understanding the theoretical foundations, algorithmic approaches, and practical considerations enables effective application of POS tagging in diverse NLP scenarios. The choice between different algorithms and configurations depends on specific requirements for accuracy, speed, and available training data.