
Data Clustering: K-means, MST based
1. What is the primary purpose of clustering in data analysis?
Q2. Which algorithm is most suitable for these data points?

Q3. Let , , and , and consider the following 3 partitions:
i) ,
ii) ,
iii) ,
Which partition is favored by the sum-of-squared error? Squared error for each partition is defined by:
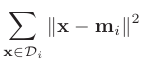 Where is the mean of partition .
Where is the mean of partition .
i) ,
ii) ,
iii) ,
Which partition is favored by the sum-of-squared error? Squared error for each partition is defined by:
Where is the mean of partition .
Q4. In MST-based clustering, how is the final clustering result determined?
Q5. What is the main advantage of using MST-based clustering over K-means?
Q6. What is the role of the minimum spanning tree in MST-based clustering?