
To study and implement the K-NN Classifier for pattern recognition and prediction
Introduction
The k-nearest neighbors algorithm, commonly referred to as KNN or k-NN, represents a non-parametric supervised learning classifier. This approach relies on proximity to categorize or forecast the affiliation of a specific data point. Its fundamental premise revolves around the idea that closely situated points tend to exhibit similarities, forming the basis for its decision-making process. It is also called a lazy learner algorithm because it does not learn from the training set immediately; instead, it stores the dataset, and at the time of classification, it performs an action on the dataset.
Why do we need K-NN algorithm?
It is primarily used for its simplicity and ease of implementation. The algorithm does not require any assumptions about the underlying data distribution. Additionally, it can handle both numerical and categorical data, making it a flexible choice for various types of datasets in classification and regression tasks. K-NN is a non-parametric method that makes predictions based on the similarity of data points in a given dataset. Furthermore, K-NN is less sensitive to outliers compared to other algorithms.
The K-NN algorithm works by finding the K nearest neighbors to a given data point based on a distance metric, such as Euclidean distance. The class or value of the data point is then determined by the majority vote or average of the K neighbors. This approach allows the algorithm to adapt to different patterns and make predictions based on the local structure of the data.
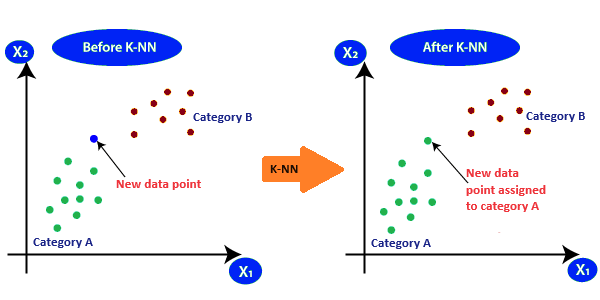
For example, let's consider two categories, namely Category A and Category B. Now, suppose we have a new data point, x1. The question arises: in which of these categories does this data point belong? To address such problems, we rely on the K-NN algorithm. With the assistance of K-NN, we can effortlessly determine the category or class of a specific dataset. Consider the below diagram:
Distance Metrics Used in K-NN Algorithm:
Euclidean Distance: Euclidean distance can be visualized as the length of the straight line that joins the two points which are into consideration. This metric helps us calculate the net displacement done between the two states of an object.
d = √ ((X2 - X1)² + (Y2 - Y1)²) Where,
“d” is the Euclidean distance,
"Xi" is the x axis of data point,
"Yi" is the y axis of Data pointManhattan Distance: It is a distance metric between two points in an N-dimensional vector space. It is defined as the sum of absolute distance between coordinates in corresponding dimensions. If two points are in the form (X1, Y1) and (X2 , Y2). Then,
Manhattan distance = |X1 – X2| + |Y1 – Y2| Minkowski Distance: This distance measure is the generalized form of Euclidean and Manhattan distance metrics. It is used for distance similarity of vector. The parameter, p, in the formula below, allows for the creation of other distance metrics. Euclidean distance is represented by this formula when p is equal to two, and Manhattan distance is denoted with p equal to one.
How to choose the value of k for K-NN Algorithm?
The value of k in the k-NN algorithm should be chosen based on the input data. If the input data has more outliers or noise, a higher value of k would be better. It is recommended to choose an odd value for k to avoid ties in classification. Cross-validation methods can help in selecting the best k value for the given dataset.
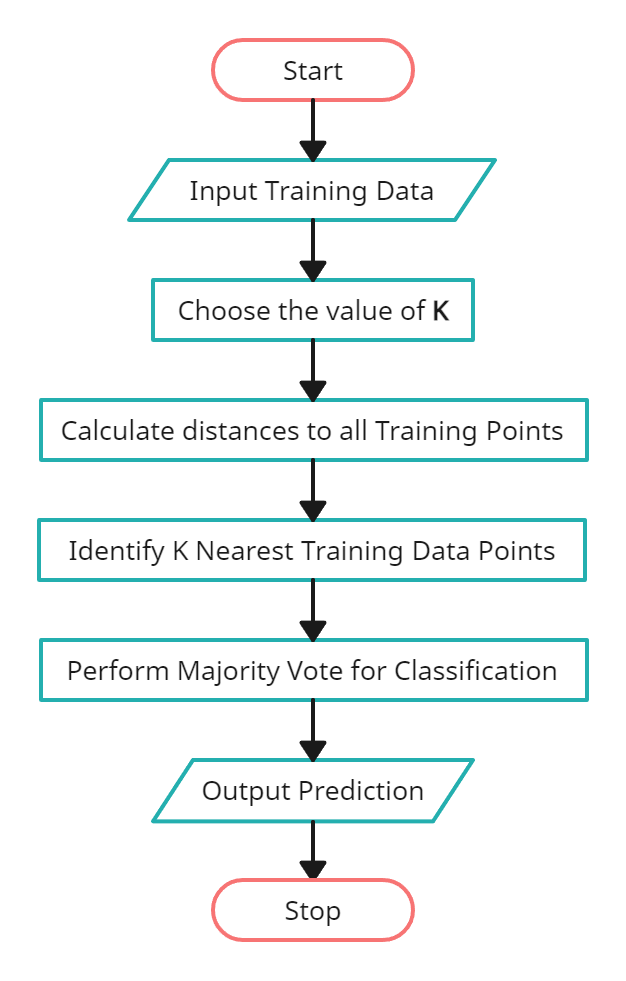
The k-NN algorithm works as follows:
- Initialize value of K.
- Calculate distance between testing data and training dataset.
- Sort the distances.
- Take top K- nearest neighbors.
- Apply simple majority.
- Predict class label with more neighbors for testing data.
EXAMPLE
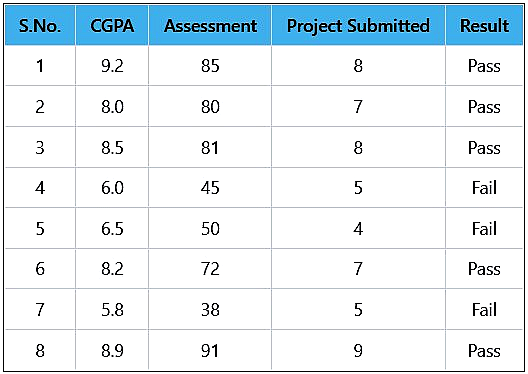
Problem Statement: Consider a training dataset given in below table. Use K-NN Supervised Learning Algorithm to determine the class for test instance (7.6, 60, 8).
-->
Solution:
Step 1: Input Training and Test Data
Given a test instance(6.1, 40, 5) and a set of categories {'Pass', 'Fail'} also called a classes, we need to use the training set to classify the test instance using Euclidean distance.
Step 2: Choose the value of k
Assign k = 3.
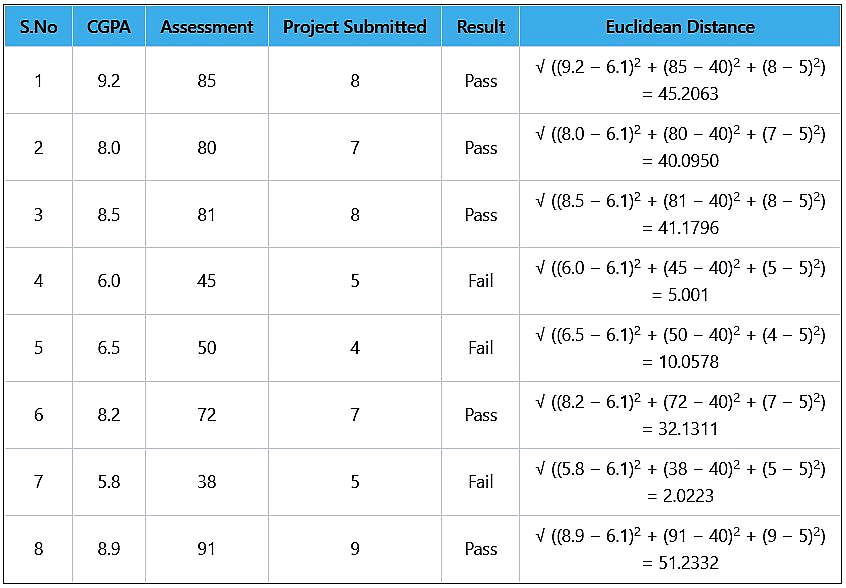
Step 3: Calculate the Euclidean distance between the test instance (6.1, 40, 5) and each of the training instances as shown in Table 2.
Step 4: Identify K Nearest Training Data Points
Sort the distances in the ascending order and select the first 3 nearest training data instances to the test instance. The selected nearest neighbours are shown in below Table 3.
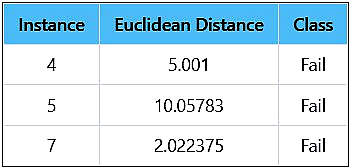
Step 5: Predict the class of the test instances 4, 5 and 7 with smallest distances.
Step 6: The class for the test instance is predicted as 'Fail'.
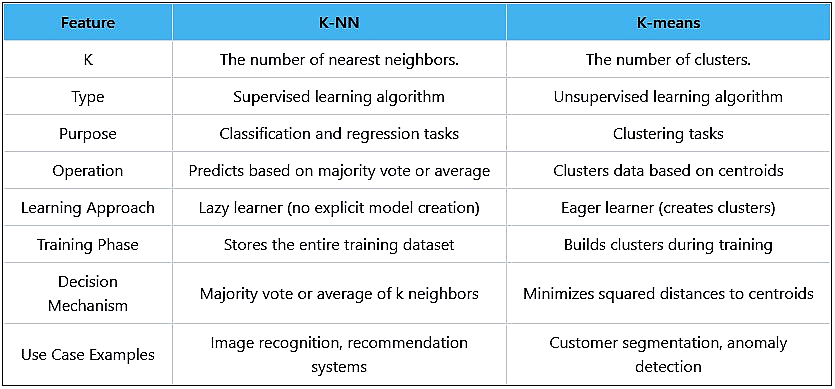
What is the difference between K-NN, and K means?
K-NN and K-means are two distinct algorithms used in different types of machine learning tasks, and they serve different purposes:
Some Applications of K-NN:
- Image and Pattern Recognition: KNN can be used for image recognition and pattern matching tasks, where it classifies images based on the similarity of their features to those in the training set.
- Recommendation Systems: KNN is employed in collaborative filtering for recommendation systems. It recommends items to users based on the preferences and behavior of users with similar tastes.
- Natural Language Processing (NLP): KNN can be applied in NLP tasks, such as text classification and sentiment analysis, by comparing the textual features of documents or sentences.
Advantages
- Simplicity and Ease of Implementation: KNN is a straightforward algorithm that is easy to understand and implement.
- Versatile: KNN can be applied to both classification and regression problems. Whether you're dealing with categorical or numerical data, KNN can adapt to different types of problems.
- No Training Phase: KNN is a lazy learner algorithm, meaning it doesn't have an explicit training phase. It stores the entire dataset and makes decisions at the time of prediction.
- Few Hyperparameters: The only parameters which are required in the training of a KNN algorithm are the value of k and the choice of the distance metric which we would like to choose from our evaluation metric.
Disadvantages
- Always needs to determine the value of K which may be complex some time.
- The computation cost is high because of calculating the distance between the data points for all the training samples.
- Curse of Dimensionality: It is affected by the curse of dimensionality which implies the algorithm faces a hard time classifying the data points properly when the dimensionality is too high.
- Prone to overfitting: Due to the “curse of dimensionality”, KNN is also more prone to overfitting. While feature selection and dimensionality reduction techniques are leveraged to prevent this from occurring, the value of k can also impact the model’s behavior. Lower values of k can overfit the data, whereas higher values of k tend to “smooth out” the prediction values since it is averaging the values over a greater area, or neighborhood. However, if the value of k is too high, then it can underfit the data.
- Inefficient for Large Datasets: The algorithm's computational inefficiency becomes more pronounced with larger datasets, making it less suitable for scenarios where quick predictions are essential.
- Memory Usage: Since KNN stores the entire dataset during the prediction phase, it can be memory-intensive, particularly with large datasets.