
Error Detection and Correction, Standard Array, Syndrome Decoding
The theory associated with Experiment-4 is divided into two parts:
- Standard array decoding
- Syndrome decoding
1. Standard array decoding
The decoding consists of estimating the transmitted codeword corresponding to the given received vector. Standard array decoding is a method for decoding linear block codes when the noise is introduced by the binary symmetric channel (BSC) with cross-over probability , denoted by BSC . For a detailed description of standard array decoding, please refer to [1] (Chapter 4, Section 3.5). We shall next briefly discuss how to construct a standard array corresponding to the given linear block code and then discuss how to decode the given received vector using it.
Let be the set of codewords of the given code . A codeword is chosen randomly and transmitted over the BSC to get the received vector . Note that for the BSC, can be any vector in , irrespective of the transmitted codeword. The core idea of standard array construction consists of dividing all possible vectors into disjoint subsets such that there is exactly one codeword in each subset. Thus the given vector can be associated with the unique codeword that lies in the same subset as that of , and in standard array decoding, is decoded to this codeword.
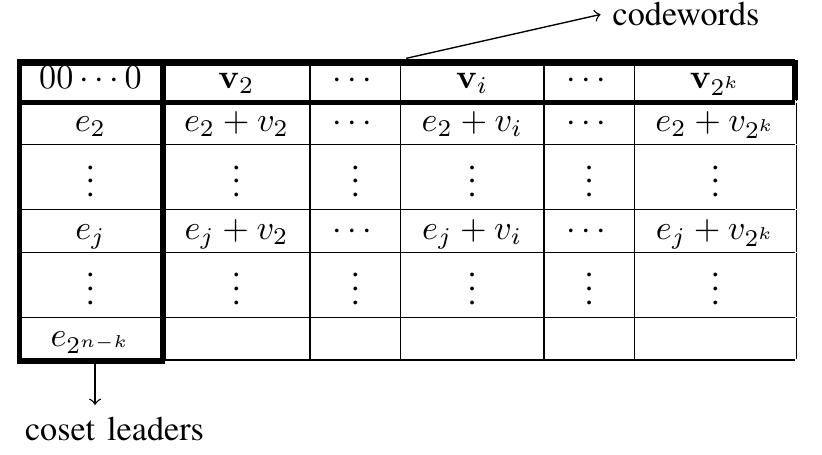
Figure 1: A general structure of the standard array
For BSC with , an optimal way of dividing these vectors into disjoint subsets provides a standard array. A standard array is a table with columns and rows such that a distinct vector in is placed in each entry of this table. For the given row, the vector in the first column is called the coset leader of that row. The procedure for constructing a standard array is provided below:
- First row: Put the all-zero codeword in the first row and the first column. Thus, the all-zero vector is the coset leader of the first row. The remaining non-zero codewords are placed in the remaining columns of the first row. Without loss of generality, let be the all-zero codeword and be the non-zero codewords. Then the first row of the standard array is illustrated in Figure 1.
- Rows to : For the th row, , do the following:
- Identify a vector of minimum weight that has not appeared in the rows to . This vector is chosen as the coset leader of the th row. Let denote the coset leader of the th row.
- The remaining entries in the th row are obtained by adding to the codeword corresponding to each column, i.e., the entry in the th column is given by , where (see Figure 1).
Note that the set of coset leaders need not be unique. Further, the non-zero codewords can be placed in any order in the first row of the standard array. Hence, a standard array corresponding to the given code is not unique. Let us consider an example for standard array construction.
Example 1:
Let be the set of codewords of a linear block code of length . Note that the dimension of this code is . A standard array corresponding to this code is given in Table 1. It can be verified that this standard array is not unique.
Table 1: Standard array of a linear block code of length 5
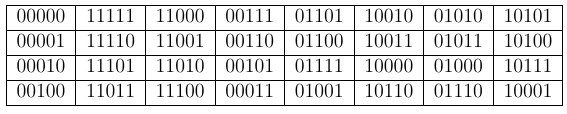
Let us now discuss how to decode the given received vector using the standard array. This procedure is summarized below:
- Locate in the standard array. Suppose lies in the th column.
- is decoded as , which is the codeword corresponding to the th column.
Suppose is the transmitted codeword and is the error introduced by the BSC, then the received vector will be . Observe that we will be able to correct such an error pattern via standard array decoding. It can be shown that the set of coset leaders are the set of error patterns that can be corrected using standard array decoding.
2. Syndrome decoding
For the given linear block code with parity check matrix , the syndrome of the given vector is defined as the vector given by
Consider the following properties of syndromes (proofs can be found in [1]):
- Property 1: Syndromes of the vectors that lie in the same row of the standard array are the same, i.e., for and that lie in the same row of the standard array we have
- Property 2: Syndromes of the vectors that lie in different rows of the standard array are different, i.e., for and that lie in different rows of the standard array we have
Properties 1 and 2 indicate that there are exactly distinct syndromes and these are the syndromes of the coset leaders. One only needs to keep track of the coset leaders and their corresponding syndromes and simplify the standard array decoding procedure as follows:
- For the given received vector , compute its syndrome .
- Locate the coset leader whose syndrome is equal to this , i.e., locate coset leader such that .
- The decoded codeword is given by .
It can be verified that the standard array and syndrome decoding are equivalent and would decode the given to the same codeword. The advantage of syndrome decoding is that the storage space required is less as compared with standard array decoding.