
To build and evaluate a Decision Tree using the ID3 algorithm
Introduction
Decision trees are powerful and widely used supervised learning algorithms that are capable of performing both classification and regression tasks. They are popular due to their simplicity, interpretability, and ability to handle both numerical and categorical data.
Structure of Decision Trees:
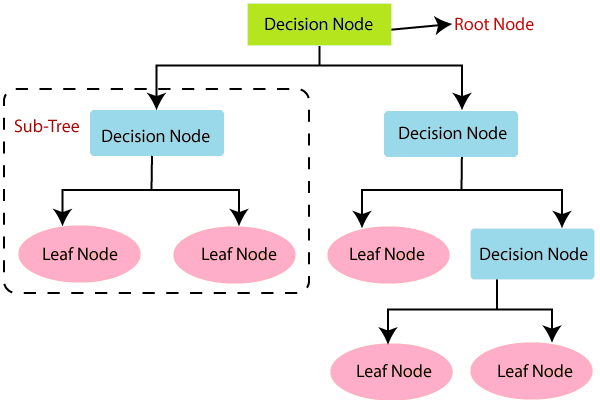
At its core, a decision tree is a hierarchical structure consisting of nodes and edges. Each node represents a decision or a feature test, and each edge represents the outcome of that decision, leading to either another decision node or a leaf node.
- Root Node : Root node is from where the decision tree starts. It represents the entire dataset, which further gets divided into two or more homogeneous sets.
- Leaf Node : Leaf nodes represent the final outcome or the class label (in classification tasks) or a numerical value (in regression tasks), and the tree cannot be segregated further after getting a leaf node.
- Splitting : Splitting is the process of dividing the decision node/root node into sub-nodes according to the given conditions.
- Branch/Sub Tree : A tree formed by splitting the tree.
- Pruning : Pruning is the process of removing the unwanted branches from the tree.
- Parent/Child node : The root node of the tree is called the parent node, and other nodes are called the child nodes.
Splitting Criteria:
There are several commonly used splitting criteria, including:
Information Gain
- It is the measurement of changes in entropy after the segmentation of a dataset based on an attribute.
- It calculates how much information a feature provides us about a class.
- According to the value of information gain, we split the node and build the decision tree.
- A decision tree algorithm always tries to maximize the value of information gain, and a node/attribute having the highest information gain is split first. It can be calculated using the below formula:
where,IG(D, A) = H(D) - H(D∣A)
- IG(D,A) is the information gain of splitting dataset D based on attribute A.
- H(D) is the entropy of the dataset D.
- H(D∣A) is the conditional entropy of D given the attribute A.
Entropy: Entropy is a metric to measure the impurity in a given attribute. It specifies randomness in data. Entropy can be calculated as:
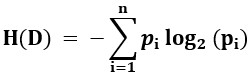
- pi is the proportion of examples in class i in the dataset D.
- n is the number of classes.
And the conditional entropy H(D∣A) is calculated as the weighted average of the entropies of each partition of the dataset based on the values of attribute A:
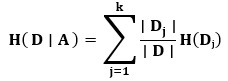
- k is the number of values of attribute A.
- ∣Dj∣ is the number of examples in partition j.
- ∣D∣ is the total number of examples in the dataset.
Gini Index : Measures the probability of misclassifying an instance if it were randomly labeled according to the distribution of classes in a subset.
Chi-Square : Tests the independence between a feature and the target variable.
How does the Decision Tree algorithm Work?
- Begin the tree with the root node, says S, which contains the complete dataset.
- Find the best attribute in the dataset using Attribute Selection Measure (ASM).
- Divide the S into subsets that contains possible values for the best attributes.
- Generate the decision tree node, which contains the best attribute.
- Recursively make new decision trees using the subsets of the dataset created in step -3. Continue this process until a stage is reached where you cannot further classify the nodes and called the final node as a leaf node.
ID3 Algorithm
ID3 stands for Iterative Dichotomiser 3, and it is named as such because the algorithm iteratively (repeatedly) dichotomizes (divides) features into two or more groups at each step. This algorithm is a classic machine learning technique used for constructing decision trees. Developed by Ross Quinlan, ID3 is widely recognized for its simplicity and effectiveness in decision tree induction. This algorithm is particularly suitable for solving classification problems by recursively partitioning the dataset based on the attributes that best separate the classes.
Steps involved in ID3 algorithm?
- Determine entropy for the overall the dataset using class distribution.
- For each feature: Calculate Entropy for Categorical Values. Assess information gain for each unique categorical value of the feature.
- Choose the feature that generates highest information gain.
- Iteratively apply all above steps to build the decision tree structure.
Advantages of Decision Trees
- Simple to understand and interpret, making them suitable for explaining decision-making processes to non-experts.
- Can handle both numerical and categorical data without the need for feature scaling or one-hot encoding.
- Non-parametric, meaning they have no assumptions about the underlying distribution of the data.
- Able to capture complex decision boundaries and interactions between features.
Disadvantages of Decision Trees
- Tendency to overfit, especially when the tree is allowed to grow too deep.
- Can be sensitive to small variations in the training data.
- Biased towards features with more levels, which can lead to the over-representation of such features in the tree.
- Lack of smoothness in predictions, especially in regression tasks where the predictions are piecewise constant.
- Decision trees take a greedy search approach during construction, they can be more expensive to train compared to other algorithms.