
Data Preprocessing
Step 1: Click on the "Load Dataset for Preprocessing" button to begin the simulation.
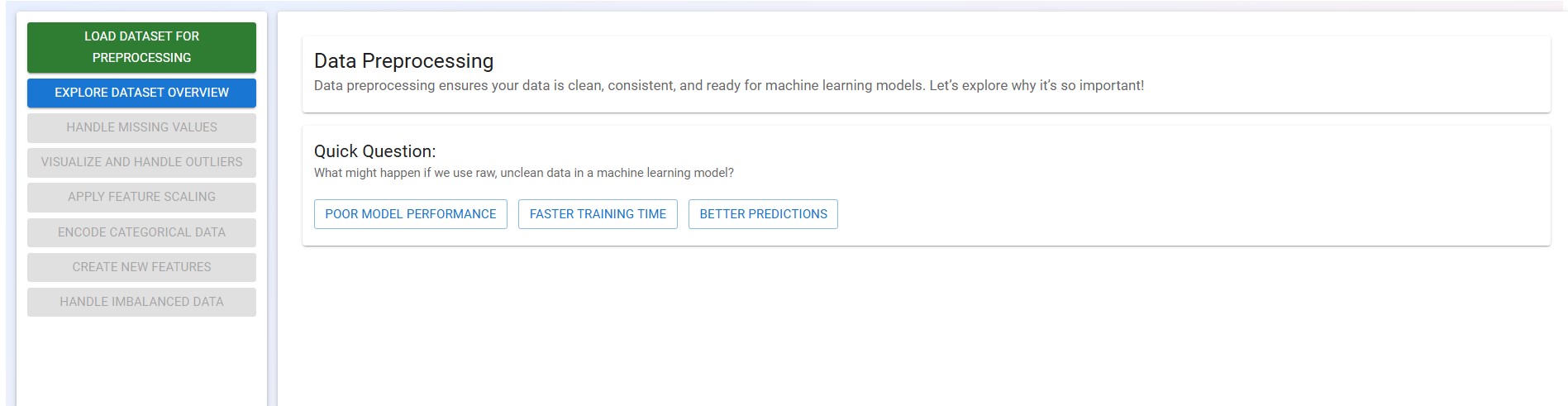
Step 2: Click on the "Show Dataset" button to display the dataset. Hover over the dataset table to identify potential issues such as missing values, outliers, or inconsistencies.
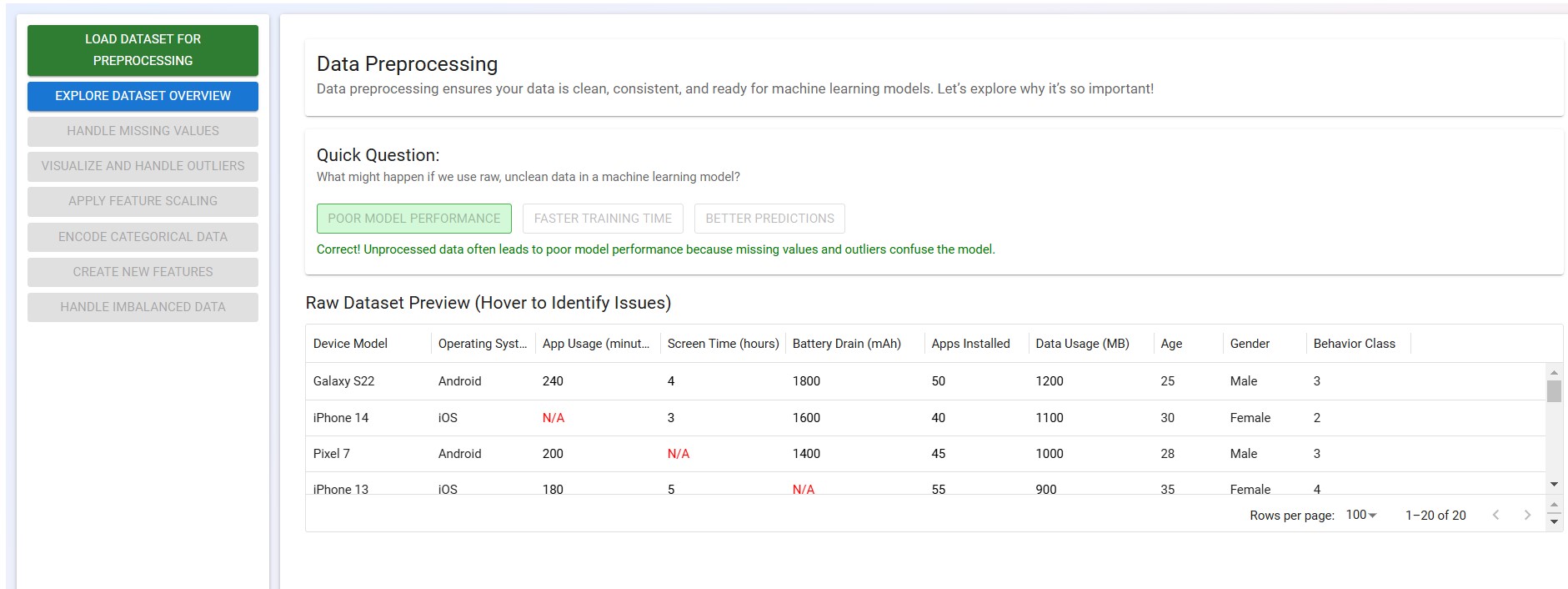
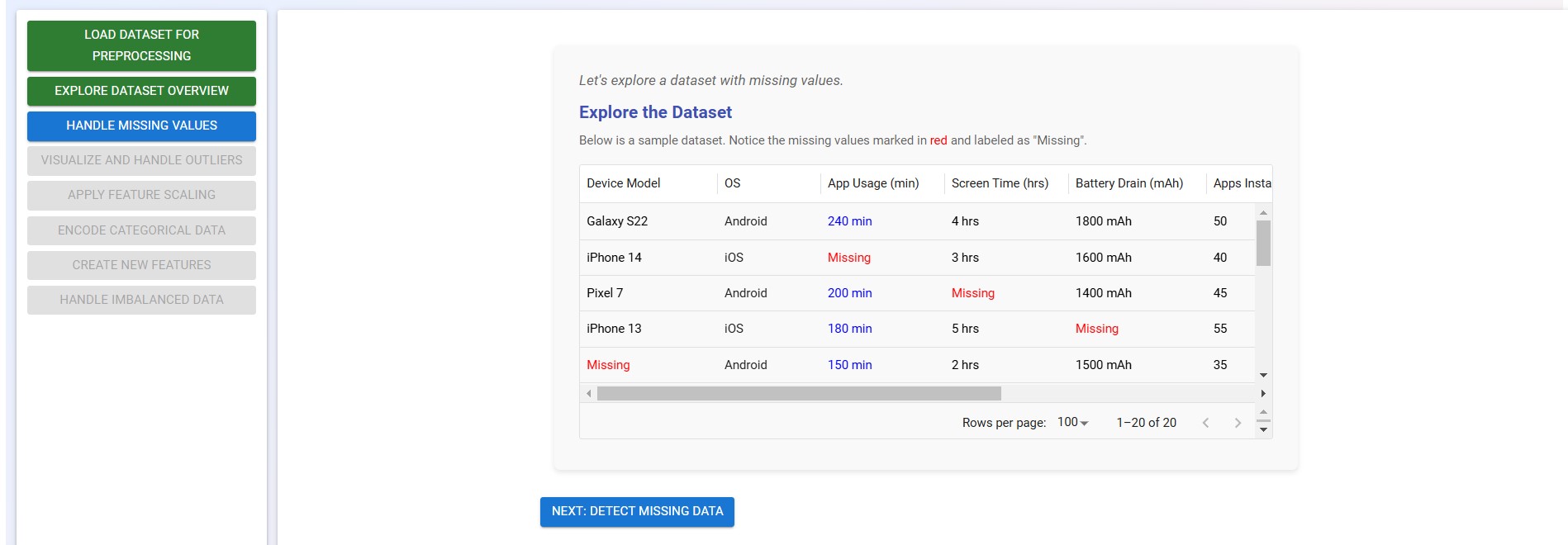
Step 3: Click on the "Explore Dataset Overview" button to examine missing values. The first step in data preprocessing is to observe the dataset and identify any missing values.
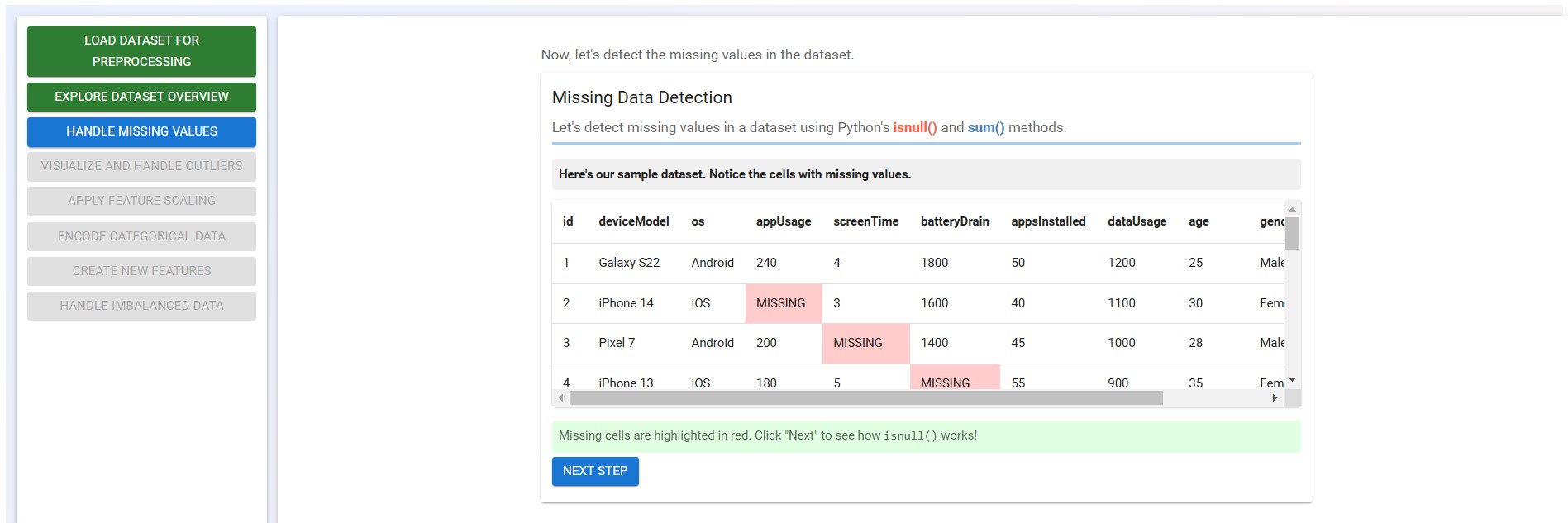
Click on the "Detect Missing Data" button to identify missing values in the dataset using Python’s isnull() and sum() methods.
Click on "Next" to learn how the isnull() method works!
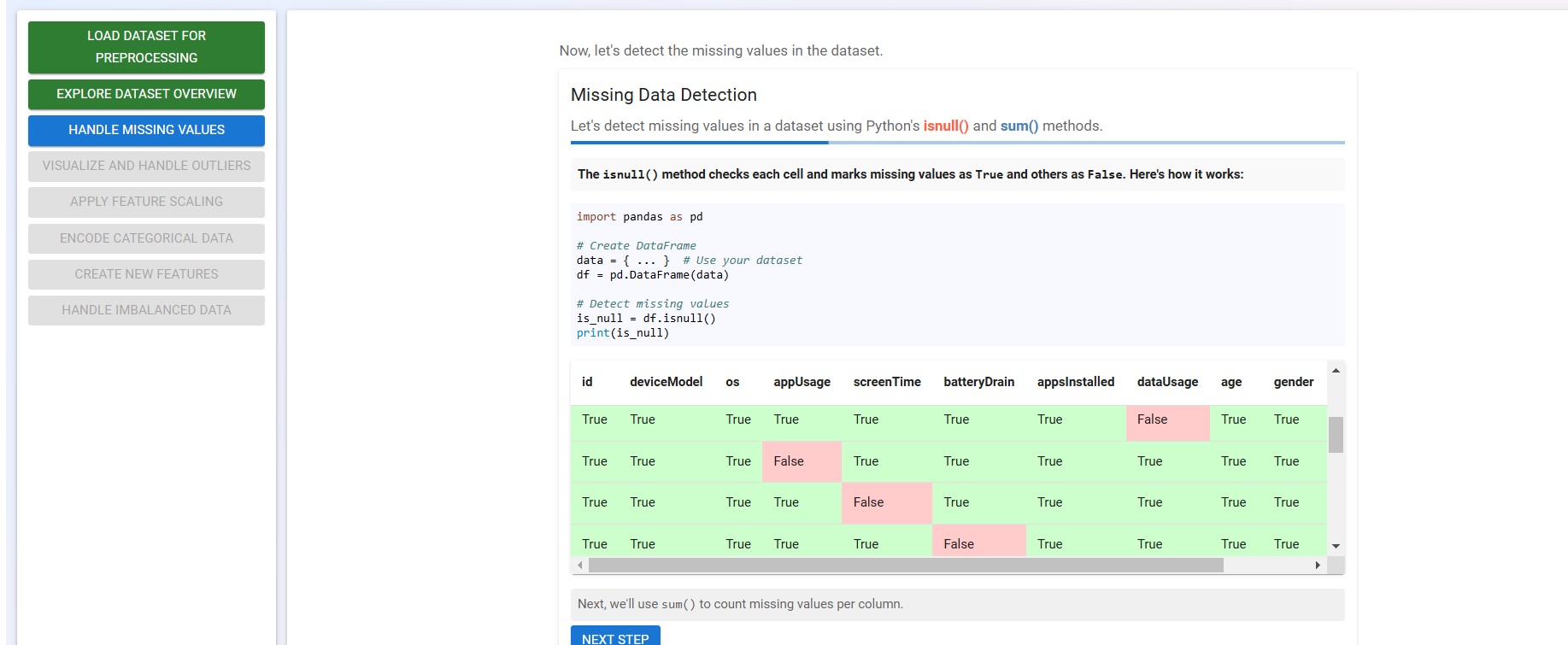
Click on the "Next" button to see how we can use the code>sum() method to count the missing values per column.
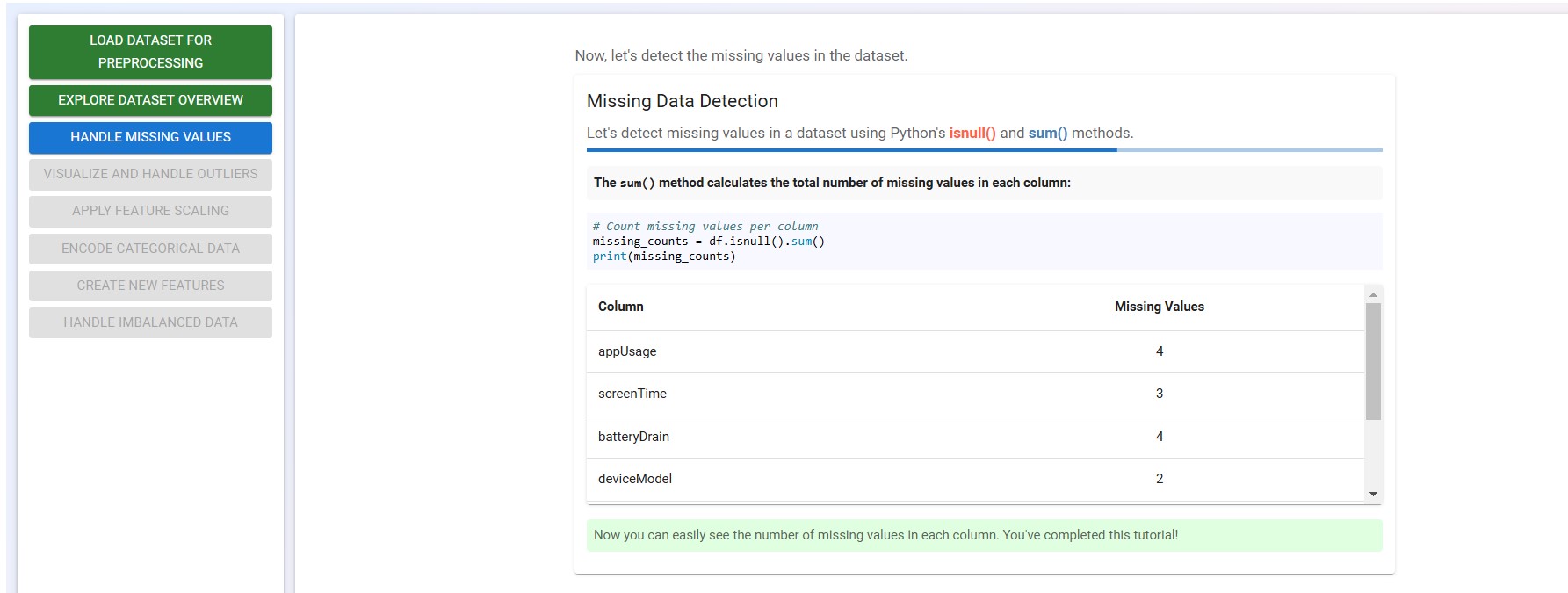
Congratulations! You've completed this tutorial and successfully finished the first step in data preprocessing!
Click on the "Handle Missing Values" button from the main options on the left side to proceed.
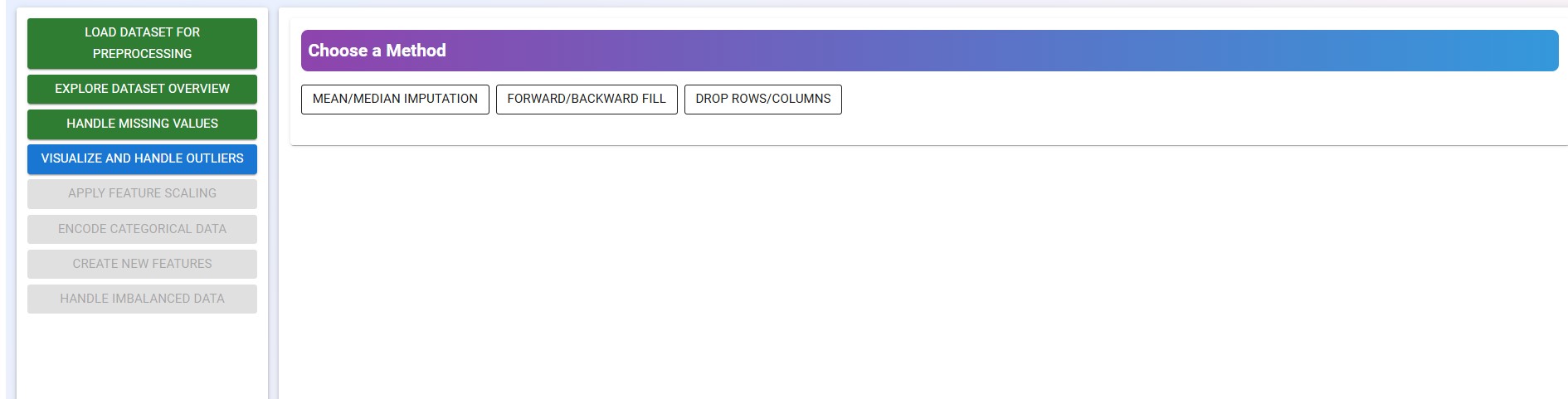
Choose one of the methods below to handle the missing values in the dataset:
- Mean/Median Imputation
- Forward Fill / Backward Fill
- Remove Rows/Columns with Missing Values
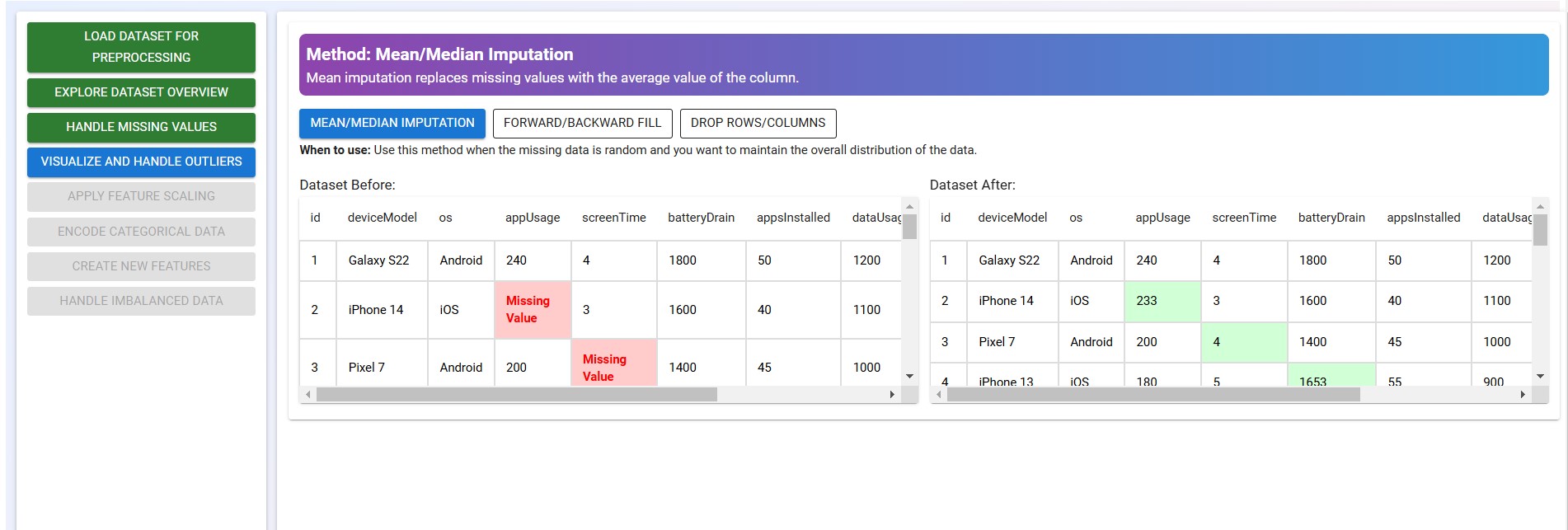
Click on the "Mean/Median Imputation" button to observe and understand how the method works.
Click on the "Forward Fill", "Backward Fill", and "Remove Rows/Columns" options to view and understand how each method works.
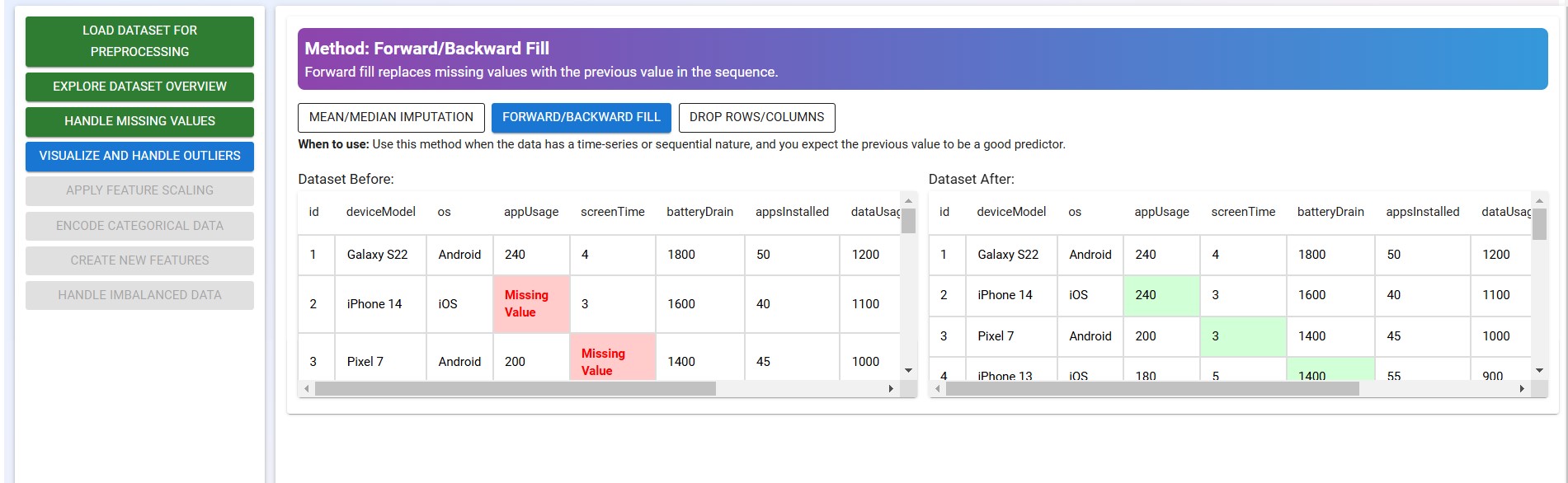
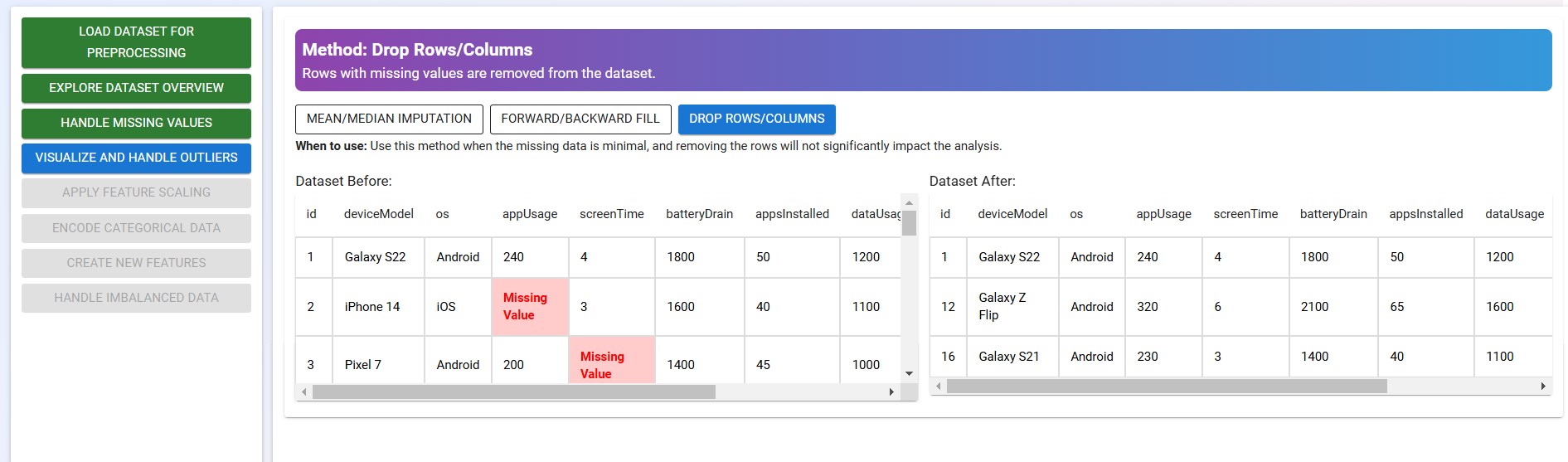
Well done! You've successfully completed this tutorial and finished the second step in data preprocessing!
Click on the "Visualize and Handle Outliers" button to proceed to the next step in data preprocessing.
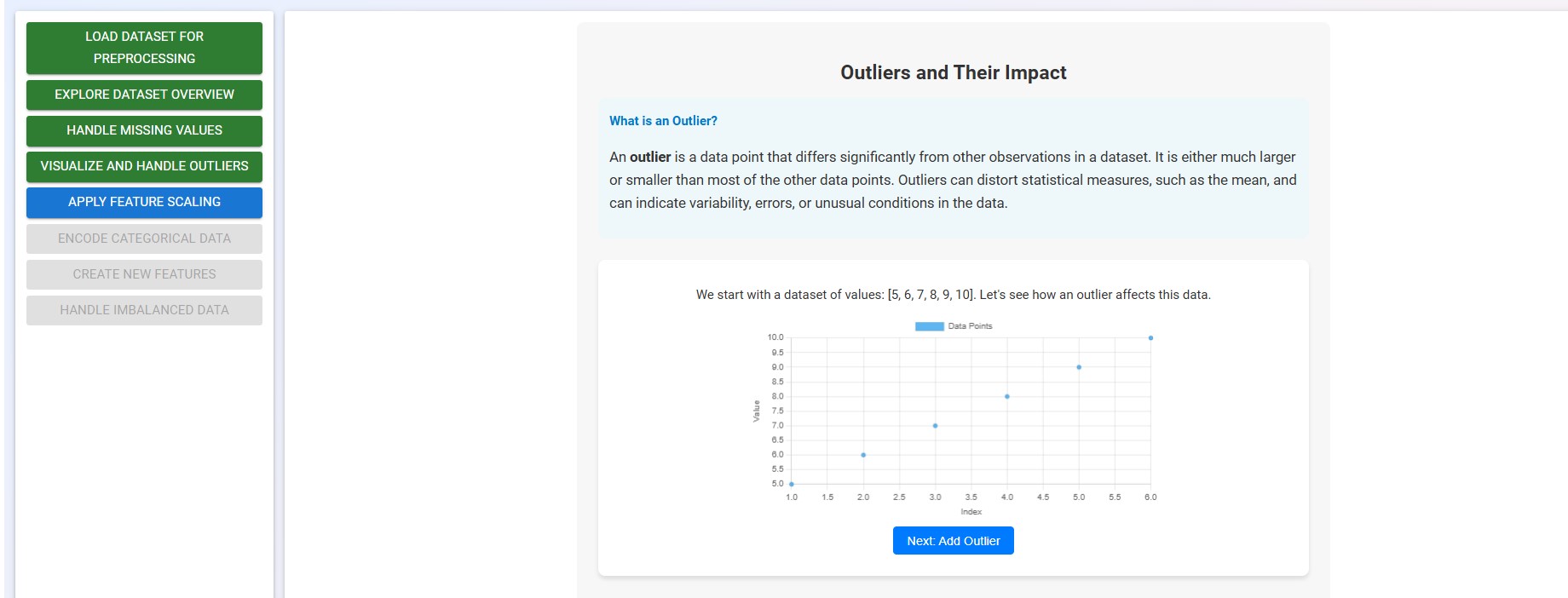
Carefully review the section to understand what outliers are and how they can impact the dataset.
Click on the "Add Outlier" button to proceed.
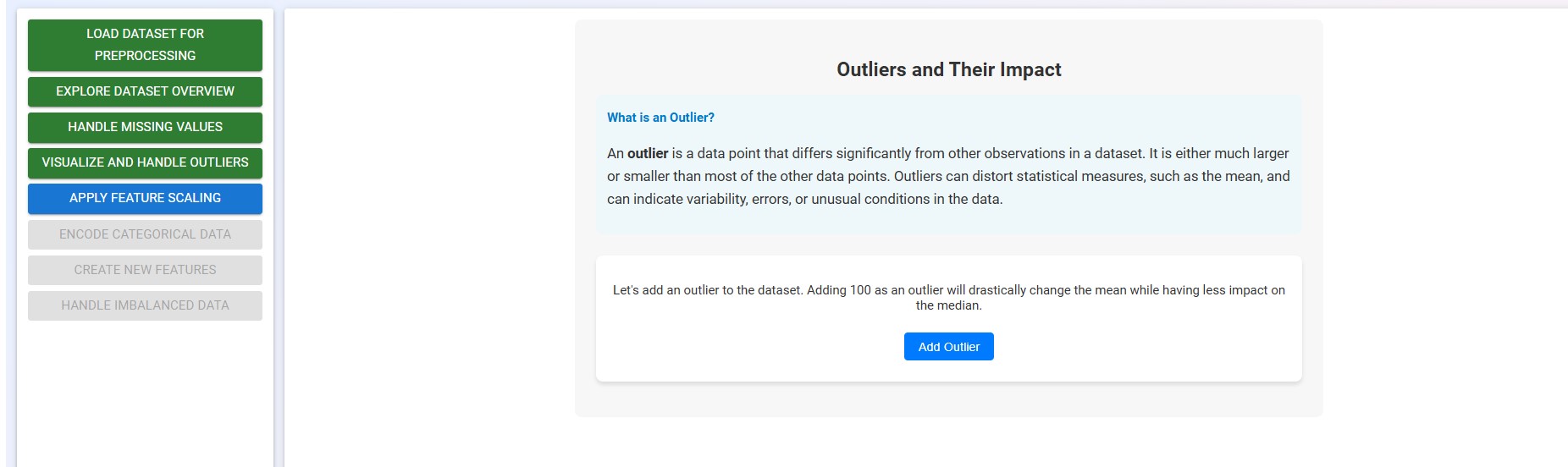
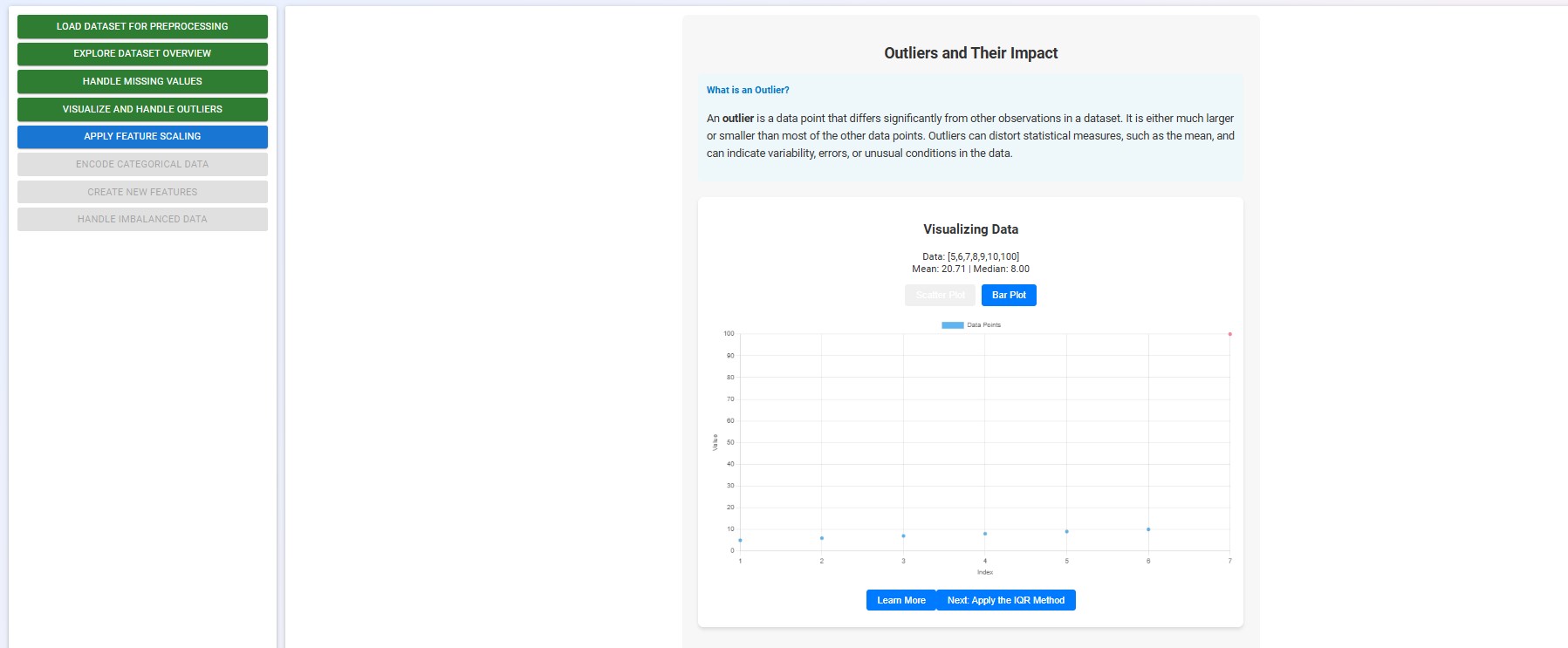
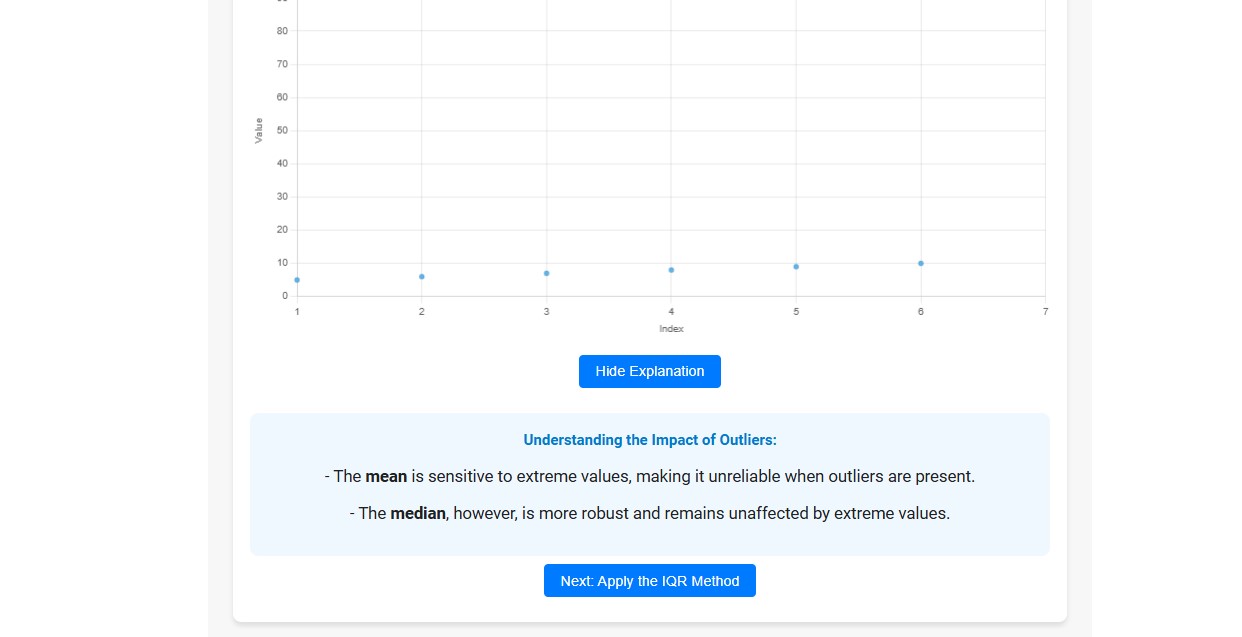
Click on the "Learn More" button to understand the impact of outliers on the dataset.
Click on the "Apply IQR" button to learn how to apply the Interquartile Range (IQR) method for detecting outliers in the preprocessed data.
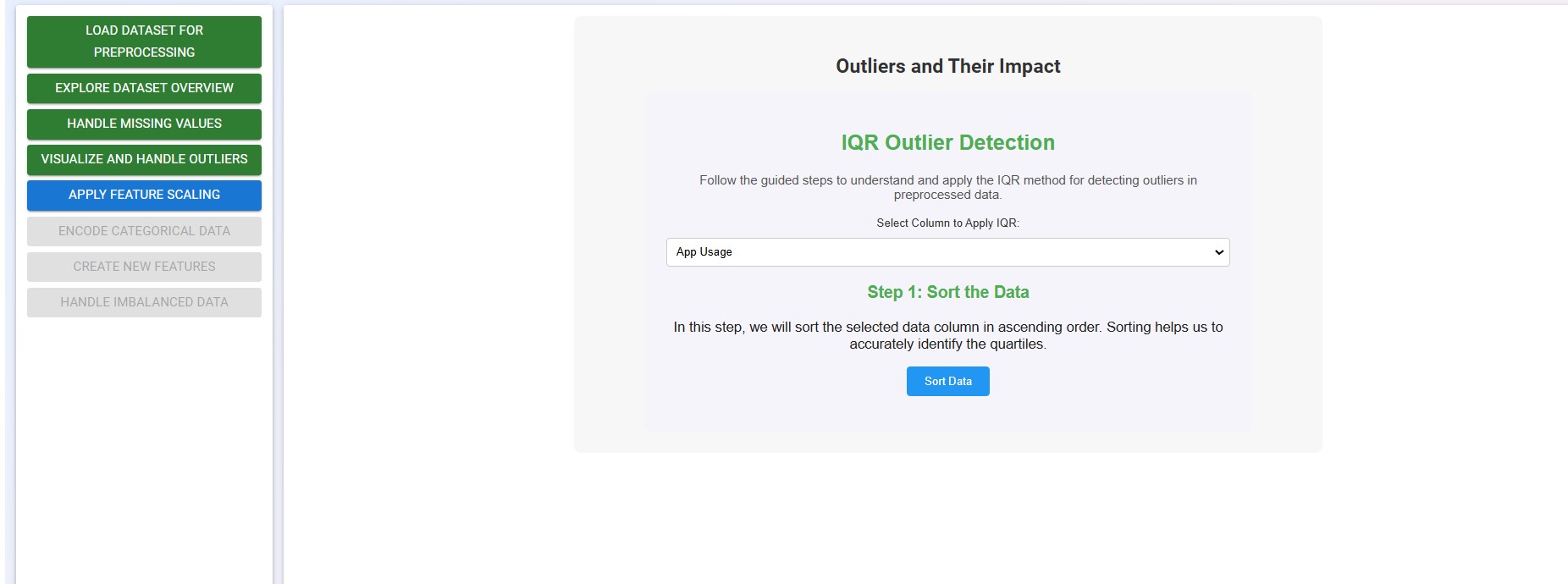
Follow the guided steps to understand and apply the IQR method for detecting and handling outliers in preprocessed data.
Similarly, explore the remaining steps in data preprocessing (feature scaling, encoding, feature engineering, etc.) and understand their importance in the machine learning pipeline.