
To study and perform the Candidate-Elimination algorithm for concept learning
Introduction
The Candidate Elimination algorithm is a machine learning technique employed for concept learning and hypothesis space exploration. It represents an expanded version of the Find-S algorithm and encompasses both positive and negative examples in its learning process. In this algorithm, positive examples are utilized similarly to the Find-S algorithm, essentially involving generalization from the provided specifications. Conversely, negative examples are considered in a more generalized form during the learning process. This dual consideration of positive and negative instances contributes to a comprehensive and adaptive approach in refining the hypothesis space and achieving effective concept learning.
Terms Used:
Concept learning: Concept learning is basically the learning task of the machine (Learn by Train data)
Instance: A single input or data point for which the algorithm makes predictions.
Attribute: A characteristic or feature of an instance that is used for learning and making predictions.
Hypothesis: A specific representation of a concept that the algorithm considers. In the Candidate Elimination algorithm, hypotheses are typically represented as sets of constraints on the attributes.
General Hypothesis (G): Not Specifying features to learn the machine.
- G = { '?', '?', '?' … }
- The number of ? depends on a number of attributes.
- ? : accepts all
Specific Hypothesis (S): Specifying features to learn machine (Specific feature)
- S = { 'Ø', 'Ø', 'Ø' … }
- The number of Ø depends on a number of attributes.
- Ø : rejects all
Version Space: It’s a cross between a generic and a specific theory. It doesn’t simply propose one hypothesis; instead, it generates a list of all feasible hypotheses based on the training data. Regarding the hypothesis space H and training examples D, the version space, denoted as VSH,D, represents the subset of hypotheses from H that are consistent with the training instances in D.
VSH,D = { h ∈ H ∣ h is consistent with D } Positive Example: An instance that is a positive example of the target concept, indicating that it belongs to the concept being learned.
Negative Example: An instance that is a negative example of the target concept, indicating that it does not belong to the concept being learned.
Consistency: Whether a hypothesis is consistent with a given example, meaning it correctly predicts the label (positive or negative) for that example.
Specialization: The process of making a hypothesis more specific by adding constraints.
Generalization: The process of making a hypothesis more general by removing constraints.
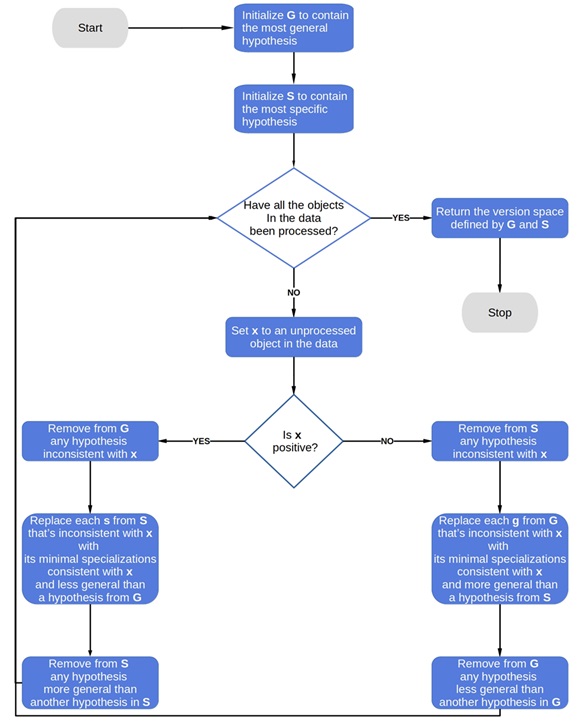
Algorithm
Step 1: Firstly, load the dataset.
Step 2: Initialize General and Specific Hypothesis.
Step 3: For each training example
Step 4: If the example is positive,
- If attribute_value == hypothesis_value then do nothing.
- Else make the attribute more general i.e replace the attribute with '?'.
Step 5: If the example is negative
- Make the generalized hypothesis more specific.
Advantages of CEA over Find-S:
- Improved accuracy: CEA considers both positive and negative examples to generate the hypothesis, which can result in higher accuracy when dealing with noisy or incomplete data.
- Flexibility: CEA can handle more complex classification tasks, such as those with multiple classes or non-linear decision boundaries.
- More efficient: CEA reduces the number of hypotheses by generating a set of general hypotheses and then eliminating them one by one. This can result in faster processing and improved efficiency.
- Better handling of continuous attributes: CEA can handle continuous attributes by creating boundaries for each attribute, which makes it more suitable for a wider range of datasets.
Disadvantages of CEA in comparison with Find-S:
- More complex: CEA is a more complex algorithm than Find-S, which may make it more difficult for beginners or those without a strong background in machine learning to use and understand.
- Higher memory requirements: CEA requires more memory to store the set of hypotheses and boundaries, which may make it less suitable for memory-constrained environments.
- Slower processing for large datasets: CEA may become slower for larger datasets due to the increased number of hypotheses generated.
- Higher potential for overfitting: The increased complexity of CEA may make it more prone to overfitting on the training data, especially if the dataset is small or has a high degree of noise.